본 글은 1월 27일 연구실 세미나 후에 정리하여 쓴 글이다.
** 서울대 박사과정 논문이다... 나도 러닝 아키텍쳐/ 파이프라인 공부를 하는 입장에서 많이 배웠다.. 열심히 하자!
Motivation
•Multi-operator pipeline vs. Single model
이 논문에서는 많은 오퍼레이터를 가진 ml 파이프라인을 싱글 모델로 대체하면 되지 않냐는 물음에 다음과 같이 대답한다. 사이킷 런 모델의 경우 최소 2개의 오퍼레이터에서 최대 43개의 오퍼레이터가 사용된다. 특히 실무에서 사용되는 ml파이프라인은 최소 수십개에서 최대 수백개의 오퍼레이터가 같이 사용되고 있다. 하지만, 본 논문에서는 많은 파이프라인을 하나의 모델로 대체했을 경우 여러가지 조합이 불가능 하다는 점에서 ML 파이프라인은 오퍼레이터 단위로써 관리되어야 한다고 한다고 서술한다. 더욱이, 새로운 파이프라인이 계속해서 제안되는 현상을 미루어 봤을때, 어떻게 오퍼레이터가 유기적으로 합쳐지고 활용되는지는 매우 중요한 요소이다.
따라서 본 논문은 파이프라인 오퍼레이터를 유기적으로 연결하는 것을 목표로 한다. 각 오퍼레이터가 유기적으로 연결된다는 뜻은 곧 딥뉴럴네트워크 형태로 변환이 가능하다는 뜻으로 해석 가능하다. 특히, 본 논문에서 제안하는 파이프라인은 End to End 의 파이프라인을 구성하는 것에 목적을 두고 있다. 기존 ml 파이프라인을 구성하는 오퍼레이터는 개별적으로 학습해 파라미터를 유지해야 하며, 하나의 문제를 해결하기 위해 네트워크 전체를 목적에 맞게 튜닝하기가 힘들다. 따라서, End to End 파이프라인은 문제 해결에 있어 긍정적인 영향을 미친다.
하지만, 모든 오퍼레이터를 유기적으로 연결하는 것에는 큰 어려움이 존재한다. 미분 불가능한 오퍼레이터가 존재하기 때문이다. Decision Tree , Word Tokenizing과 같이 미분이 근본적으로 존재하지 않는 오퍼레이터가 존재한다. 따라서, 본 논문에서 이를 그대로 활용하지 않고, 네트워크 기반으로 오퍼레이터를 Translate 한다.
PipeLine Translation

Figure 1 은 본 논문에서 제안하는 방법론이다. 위의 파이프라인은 기존 ML Pipeline / 아래의 파이프라인은 본 논문에서 제안하는 WIND TUNNEL 의 방식을 채택한 Neural Network 기반의 Pipeline이다.
Operator는 다음과 같이 구분된다.
- Arithmetic Operator
- Parametric (ex. SVM)
- Non-Parametric (ex. Sigmoid Fn)
- Algorithmic Operator
- 단순 숫자로 구현되는 것이 아닌 알고리즘적 방법론으로 구성되는 Operator
Operator는 각 소단원으로 변형되는 형태를 서술할 것이다.
Pipeline Translate – Arithmetic Operator (Non parametric)
Arithmetic Operator (Non parametric)은 sigmoid function과 같이 내부적으로 계산되는 파라미터 없이 input만 있다면 바로 Output을 추출할 수 있는 Operator를 일컫습니다. 해당 오퍼레이터는 단순 Translation 을 진행하였고 특별히 요구된 지식이 없다고 합니다.
Pipeline Translate – Arithmetic Operator (parametric)
Arithmetic Operator(Parametric)는 SVM과 같이 내부적으로 파라미터가 계산되는 Operator를 의미한다. 산술적 오퍼레이터는 보통 다음과 같이 구성된다. 먼저 예측을 하고, 로스값을 구한 후, 러닝 알고리즘을 통해 모델이 학습된다. 하지만 본 논문에서 발견한 Crucial Observation은, 한번 모델이 정의된 후 파라미터는 변하지 않는다는 것이다. 즉 새로운 데이터에 대한 정보는 계속 무시된다는 것이다.
이러한 문제를 Translated 하여 학습 완료 후에도 새로운 데이터를 활용해 파라미터를 변경할 수 있도록 구조를 재조립 하였다.
Pipeline Translate - Algorithmic Operator : GBDT
Decision Tree는 부등호로 이루어진 Node 연산으로 이루어져있기 때문에 미분이 불가능하다는 문제점을 가지고 있다. 따라서 본 논문에서는 Decision Tree의 경우, (a) 그림에서 (c)의 그림과 같이 Neural Network로 형태로 Translate 한다.
방법과 공식은 다음과 같다.
- Node Function
t : Temperature이며, Default value가 1 이다. 만약 Temperature가 1보다 낮아진다면 급격히 값이 변할 수 있다고 논문에서는 서술한다.
e_{i} :canonical basic vector이다. Ax=0의 일반해를 가우스 소거법을 통해 얻어냈을 때 Solution Vector를 Canonical Vector이다. 이 Vector는 n-1차원을 표현할 수 있다고 한다.
- Leaf Logical conjunction
Leaf 가 나타내는 값은 일종의 True / False로 값이 변경된다.
C는 노드에 fn에 참여한 node의 개수이다.
따라서 최종값을 구하기 위해 Decision Tree는 위와 같은 네트워크 구조로 변형할 수 있다. 이 구조들은 모두 미분 가능하도록 구성되어 앞, 뒤의 오퍼레이터와 유기적으로 연결될 수 있다는 것에서 큰 장점을 가지고 있다.
이후 최종 값을 계산하기 위해 T(x)가 계산되는데 다음과 같이 계산된다. -->
Vi 는 i번째 leaf의 output 값이다. ( ex. V_3 = 30)
본 논문에서는 튜닝과 인덕티브 바이어스를 선택하기 위해 3가지의 레벨을 설정했습니다. 각 레벨이 증가할 수록 많은 수의 파라미터를 튜닝할 수 있으며 조금 더 세심해진다. 특히 L4에 대해서 이야기 하는데 L4와 같이 튜닝한다는 뜻은 네트워크 전체를 튜닝할 수 있다는 뜻과 같기 때문에 풀리 커넥티드 되어 있다는 뜻이라고 논문에서는 서술합니다.
Pipeline Translate - Algorithmic Operator : Categorical
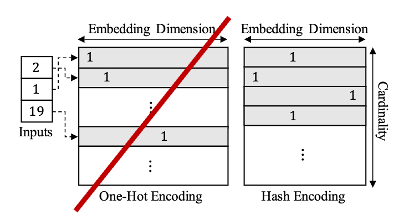
One hot encoding은 모든 Unique value를 변형하는 만큼 백터 공간이 넓어져 차원의 저주에 걸릴 뿐만 아니라, 소수의 빈도를 가진 값들은 Sparse하게 값이 반영된다. 이러한 문제점을 본 논문에서는 파악, 이를 hash Encoding으로 변형한다. 이로써, Sparse 보다는 Dense하게 각 값들을 모두 반영하여 결과값을 추출할 수 있다.
해쉬함수는 각 관계를 반영해 값을 설정하지만, 같은 값을 가지는 Collision 문제가 발생 할 수 있다고 이야기한다. 하지만 row가 다르기 때문에 row별 파라미터를 반영해 개별 객체로 인식할 수 있다고 서술한다.
Transfer Learning
이렇게 번역한 모델을 바탕으로 전이학습을 진행한다면 크게 3가지 장점을 가질 수 있다.
- NN을 FineTuning 함으로써 모델 전체가 하나의 목적을 위해 일반화 할 수 있다. (End to End)
- 각 모델별로 독자적인 Loss를 반영하기 때문에 각 다른 목적에 맞게 적용 가능하다.
- 새로운 데이터 유입에 있어 큰 문제가 발생하지 않는다.
Experiments
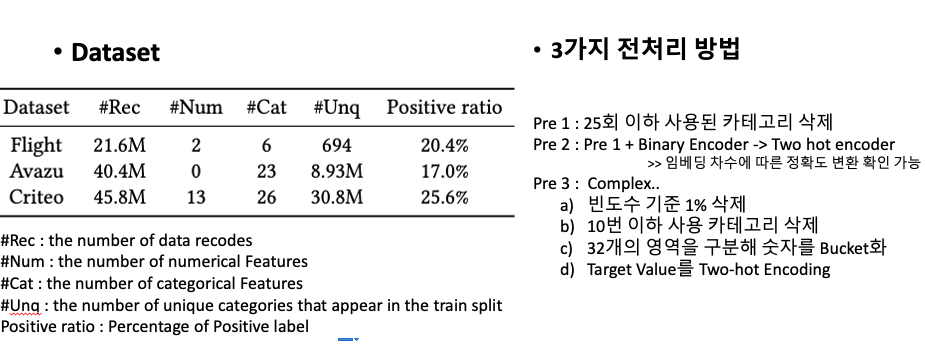
- ML Pipeline 1 : Logistic regression Model
- ML Pipeline 2 : GBDT model
- ML Pipeline 3 :
- a)Preprocessing
- b)GBDT model
- c)실행된 Leaf node에 1 , 나머지 0 을 표하는 one-hot vector를 구성
- d) C의 결과를 Factorization Machine에 Input
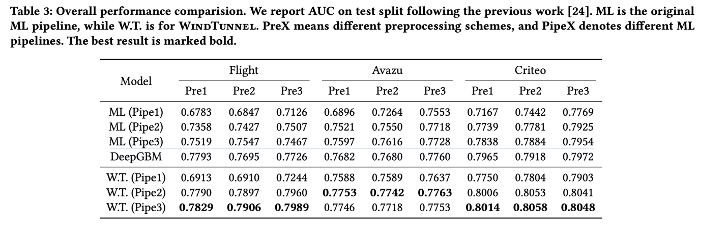
전반적으로 WT 의 성능이 약 10% 상승했음을 확인할 수 있다. 또한 전반적로 DeepGBM 의 성능보다 WT의 최대 3.5% 높음을 확인할 수 있다. 이는 각 파이프라인 별 오퍼레이터가 유기적으로 연결되어 적용되었기때문에 이러한 결과가 나왔음을 예상 가능하다.
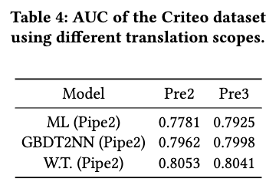
Table 4를 보면, GBDT2NN의 성능이 ML(Pipe2)성능보다 발전됨을 확인할 수 있습니다. 이는 Translation 영역이 넓을수록 정확도가 상승함을 확인할 수 있습니다. 즉, 정밀 튜닝할 수 있는 영역이 넓어질 수록 성능 개선이 일어난다는 것이다. 뿐만 아니라 GBDT2NN과 WT를 비교해 보면 WT의 성능이 더 좋은데, GBDT 모델은 Categorical Encoder가 없었음을 고려하면 Categorical Encoder가 유의미한 역할을 한다는 것을 추론 가능하다.
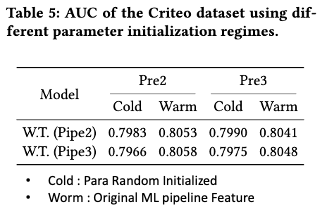
본 논문에서는 Worm이 Cold보다 좋은것을 확인 했다. Worm이 기존정보를 활용한다는 점을 고려한다면, 기존 정보를 활용한 파인튜닝 방식은 효율적이라고 서술한다.
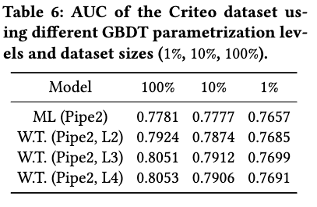
L2와 L3간의 유의미한 차이를 확인할 수 있다. 이는 flexibility 와 inductive bias 간의 tradeoff에서 유래됐다고 추측 가능하다. 따라서 데이터셋을 총 량의 10%, 1% 로 줄여서 실험을 해 본 결과 확실히 차이가 줄어듦을 확인할 수 있다. 데이터셋의 수가 줄어듦은 곧 유니크 카테고리 수가 줄어든 것을 의미한다. 즉 L3,L4는 너무 적은 데이터에 Overfitting됐다는 의미이고, 이를 종합해 보면 Level이 낮을수록 자연적인 규칙화를 제공한다는 뜻입니다.
'AI' 카테고리의 다른 글
| LLaMA: Open and Efficient Foundation Language Models (0) | 2025.02.06 |
|---|---|
| Contrastive Clustering (0) | 2023.06.08 |
| Semi-supervised Active Learning for Semi-supervised Models: Exploit Adversarial Examples with Graph-based Virtual Labels (0) | 2023.01.17 |
| 딥러닝 -03 Recurrent Neural Network (0) | 2020.04.04 |
| 딥러닝 -02 CNN 학습 (0) | 2020.03.31 |




댓글